垃圾回收问题追踪
GC 日志文件
开启 GC 日志
JDK8 GC 日志开启
-verbose:gc -Xloggc:./gc.log -XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:+UseGCLogFileRotation -XX:NumberOfGCLogFiles=5 -XX:GCLogFileSize=50M
# 开启 GC 日志输出
# 日志文件保存到当前目录下的 gc.log 文件中
# GC 日志内容包含时间戳和详细的内存变化数据
# 开启日志文件轮转,当单文件超过 50M,文件会以这样的形式存储 gc.log.0, gc.log.1, gc.log.2 ...
# 允许最多存在 5 个文件,当第 6 个文件创建时,删除最旧的那一份JDK17 GC 日志开启
-Xlog:gc*:file=./gc.log:time,uptime,level,tags:filecount=5,filesize=50M
# 参数作用和 JDK8 基本一致分析 GC 日志
JDK8 GC 日志分析
# Minor GC
2024-01-15T10:30:00.123+0800: [GC (Allocation Failure)
# 时间戳 触发原因
[PSYoungGen: 262144K->32768K(306176K)]
# 新生代:GC 前->GC 后 (总大小)
688128K->458752K(1008128K)], 0.0456789 secs]
# 整个堆:GC 前->GC 后 (总大小), 耗时
=================================================================
# Full GC
2024-01-15T10:35:00.456+0800: [Full GC (Ergonomics)
# GC 类型 触发原因
[PSYoungGen: 32768K->0K(306176K)]
# 新生代:GC 前->GC 后 (总大小)
[ParOldGen: 425984K->393216K(702464K)]
# 老年代:GC 前->GC 后 (总大小)
458752K->393216K(1008640K)]
# 整个堆内存:GC 前->GC 后 (总大小)
[Metaspace: 51234K->51234K(1099776K)], 0.2345678 secs]
# 元空间信息, GC 耗时JDK17 GC 日志分析
[2024-01-15T10:30:00.123+0800] info: GC (G1 Evacuation Pause)
# 时间戳 级别 GC 类型
safepoint.total_time=2.345ms
young=12.456ms old=0.000ms humongous=0.123ms
roots.scan_time=1.234ms
# 各项耗时详情
Heap after GC:
region 0 Eden used 32M
region 1 Survivor used 8M
region 2-10 Old used 500M
# 各个区域使用的空间堆转储文件 (heapdump)
当程序发生 OutOfMemoryError 问题时,堆转储文件 (heapdump) 往往能帮助我们追踪定位原因
导出
导出 heap dump 文件有几个方式
- 发生 OOM 时自动导出,需要增加以下 JVM 参数
java -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=./dump_demo.hprof JavaApplication - 程序运行时,使用 JDK 工具导出
- 执行
jps查看进程 ID - 执行
jmap -dump:format=b,file=jmap_dump.hprof <进程ID>
- 执行
- 程序运行时,使用 Arthas 工具导出
- 执行
java -jar ./arthas-boot.jar运行 Arthas - 选择需要导出堆转储文件的进程,进入 Arthas 控制台
- 执行
heapdump arthas_dump.hprof
- 执行
分析 heapdump 文件
常用分析工具
- Eclipse MAT
- 阿里云 ATP 平台
- VisualVM
常用功能
虽然功能名称不同工具可能命名上略有差异,但是总体上差异不大
| 功能 | 用途 | 适用场景 |
|---|---|---|
| Dominator Tree | 查看占用最大的对象 | 快速定位大对象 |
| Histogram | 统计对象数量和大小 | 找到异常数量的对象 |
| Leak Suspects | 自动分析泄漏嫌疑 | 快速诊断 |
| OQL | 使用类似 SQL 的语法查询对象 | 精确查找特定对象 |
内存泄漏定位步骤
Step 1: 打开 Heap Dump,查看 Dominator Tree
Dominator Tree 显示对象及其保留堆大小:
┌────────────────────────────────────────────┐
│ Class Name │ Retained Heap │
├─────────────────────────┼─────────────────┤
│ OrderCache │ 2,147,483,648 B │ ← 占用最大
│ ExcelExportTask │ 3,221,225,472 B │ ← 异常
│ Thread-123 │ 536,870,912 B │
└────────────────────────────────────────────┘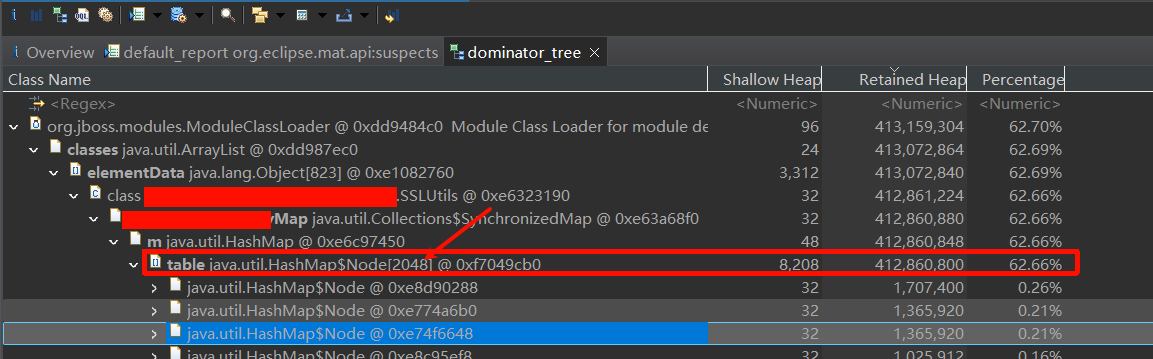
- Shallow Heap size:每一个对象自己占用的空间大小
- Retained Heap size:如果 A 对象保持着对 B 对象和 C 对象的引用,那么回收 A 对象意味着 B、C 对象都可以被回收,所以指的是这个对象及其引用对象的空间大小;也可以理解为:如果回收了它,可以释放多大的空间出来
Step 2: 查看引用链
右键对象 → Path to GC Roots → exclude weak/soft references
结果示例:
Thread-123 (main)
└─ ExcelExportTask
└─ XSSFWorkbook
└─ ArrayList
└─ 50,000 个 Row 对象 ← 问题所在Step 3: 定位代码
找到持有引用的类和方法:
- ExcelExportTask.export()
- XSSFWorkbook 未关闭
- 代码位置:com.example.service.ExcelService:45常见内存泄漏场景
场景 1: 静态集合存储大量对象未清理
// 错误示例:静态 Map 无限增长
public class CacheManager {
private static Map<String, Object> cache = new HashMap<>();
public void put(String key, Object value) {
cache.put(key, value); // 只增不减,最终导致内存泄漏
}
}
// 正确做法:使用 Caffeine 或设置容量限制
private static Cache<String, Object> cache = Caffeine.newBuilder()
.maximumSize(10000)
.build();场景 2: 资源未关闭
// 错误示例:IO 流未关闭
public void export() {
Workbook workbook = new XSSFWorkbook();
// 业务逻辑...
// 忘记 workbook.close() -> 内存泄漏
// 或者未在 final 块中执行 close() 并发生了异常 -> 内存泄漏
}
// 正确做法:try-with-resources
public void export() {
try (Workbook workbook = new XSSFWorkbook()) {
// 业务逻辑...
} // 自动关闭
}场景 3: ThreadLocal 使用完未清理
// 错误示例:ThreadLocal 未 remove
public class RequestContext {
private static ThreadLocal<User> userHolder = new ThreadLocal<>();
public void setUser(User user) {
userHolder.set(user);
}
// 没有 remove() → 线程池复用时内存泄漏
}
// 正确做法:使用后清理
public void clear() {
userHolder.remove();
}线上 GC 问题排查记录
GC 频繁导致 CPU 飙高
背景
- 系统:订单服务,JDK8
- 配置:4 核 8G,堆内存 4GB
- 现象:接口响应从 50ms 增长到 500ms,CPU 持续 90%+
优化目标
- 接口响应时间回到 50ms 到 100ms 的区间
- CPU 使用率下降到 50% 左右
排查过程
Step 1:确认 GC 情况
# 查看 GC 统计
jstat -gcutil <pid> 1000
# 输出(每秒刷新)
S0 S1 E O M CCS YGC YGCT FGC FGCT
0.00 0.00 95.31 82.45 98.12 97.56 1250 45.67 25 12.34
# 分析:
# - Eden 区 95% 使用率,频繁 Minor GC
# - 老年代 82%,接近 CMS 触发阈值
# - FGC 25 次,过于频繁Step 2:分析 GC 日志
# 日志片段
2024-01-15T10:30:00.123+0800: [GC (Allocation Failure) ...], 0.089s
2024-01-15T10:30:01.234+0800: [GC (Allocation Failure) ...], 0.095s
2024-01-15T10:30:02.345+0800: [GC (Allocation Failure) ...], 0.092s
# 1 秒 1 次 Minor GC,异常频繁!
2024-01-15T10:35:00.456+0800: [Full GC (Ergonomics) ...], 1.234s
# Full GC 耗时 1.2 秒,导致接口超时Step 3:导出堆快照
# 导出堆转储
jmap -dump:format=b,file=heap.hprof <pid>
# 使用 MAT 分析
# 发现:OrderCache 缓存占用 2GB,未设置过期策略解决方案
代码层面:
// 修复前:无限增长
Map<String, Order> cache = new HashMap<>();
// 修复后:使用 Caffeine,设置过期策略
Cache<String, Order> cache = Caffeine.newBuilder()
.maximumSize(10000)
.expireAfterWrite(1, TimeUnit.HOURS)
.build();参数调整:
# 调整前
-Xms4g -Xmx4g
# 调整后
-Xms6g -Xmx6g # 增加堆内存
-XX:NewRatio=1 # 新生代比例调整为 1:1
-XX:CMSInitiatingOccupancyFraction=75 # 提高 CMS 触发阈值效果验证
修复后:
- Minor GC 频率:1 次/秒 → 10 次/分钟
- Full GC 频率:25 次/小时 → 0 次/小时
- CPU 使用率:90% → 40%
- 接口响应:500ms → 50ms内存泄漏导致老年代持续增长
背景
- 系统:报表服务,JDK8
- 配置:8 核 16G,堆内存 8G
- 业务:每天定时导出 Excel 报表
- 现象:老年代使用率每天增长 5%,从 60% 增长到 95%,每周必定触发一次 Full GC
优化目标
- 老年代在每次 Full GC 后,使用率应该下降而不是持续增长
排查过程
Step 1: 每天使用 Arthas 工具查看老年代使用率
# 每天记录老年代使用率
jstat -gcutil <pid>
# 发现趋势
Day 1: O = 60%
Day 3: O = 72%
Day 5: O = 85%
Day 7: O = 95% → Full GC
# 确认是内存泄漏
# 老年代持续增长,Minor GC 后不降反升
# Full GC 后老年代只降到 70%,无法回到最初的 60%Step 2: 导出 heapdump 文件分析
jmap -dump:live,format=b,file=heap.hprof <pid>Step 3: 使用 MAT 工具分析
Dominator Tree 显示:
┌─────────────────────────────────────────────┐
│ Class Name │ Retained Heap │
├─────────────────────────┼──────────────────┤
│ XSSFWorkbook │ 3,221,225,472 B │ ← 占用 3GB
│ OrderCache │ 536,870,912 B │
└─────────────────────────────────────────────┘
Path to GC Roots:
Thread-15 (Excel-Export-Worker)
└─ ThreadLocal$ThreadLocalMap
└─ Entry(key=ThreadLocal, value=XSSFWorkbook)
└─ XSSFSheet
└─ 50,000 行数据Step 4: 定位代码
// 问题代码:ExcelExportService.java
public class ExcelExportService {
// ThreadLocal 存储 Workbook,方便多方法共享
private static ThreadLocal<Workbook> workbookHolder = new ThreadLocal<>();
public void exportDailyReport() {
Workbook workbook = new XSSFWorkbook();
workbookHolder.set(workbook); // 存入 ThreadLocal
try {
// 生成报表...
fillData(workbook);
writeToFile(workbook);
} catch (Exception e) {
log.error("导出失败", e);
}
// 问题:没有 workbookHolder.remove()
// workbook 残留在 ThreadLocal 中,线程池复用时不释放
}
}解决方案
代码修复:
public void exportDailyReport() {
Workbook workbook = new XSSFWorkbook();
workbookHolder.set(workbook);
try {
fillData(workbook);
writeToFile(workbook);
} catch (Exception e) {
log.error("导出失败", e);
} finally {
// 1. 使用完成后清理 ThreadLocal
workbookHolder.remove();
// 2. 关闭 Workbook (如果没有使用 ThreadLocal 可以使用 try-with-resource 来关闭)
try {
workbook.close();
} catch (IOException e) {
log.warn("关闭 Workbook 失败", e);
}
}
}效果验证
修复后监控:
Day 1: O = 45%
Day 3: O = 48%
Day 7: O = 46% → 稳定在 45-50%
Full GC:从每周 1 次 → 0 次大对象导致 Young GC 耗时增长
背景
系统:政务服务平台,JDK17
业务:每月初企业集中申报服务单据,系统需要审核企业提交的单据数据
配置:8 核 16G,堆内存 8GB,G1 收集器
高峰期特点:
- 每月 1-15 号为申报高峰期
- 高峰期每分钟处理 200+ 条申报记录
- 需要将申报数据发送到 RocketMQ,由审核服务异步处理问题现象
Prometheus 监控(申报高峰期):
─────────────────────────────────────────────
指标 正常期 高峰期
─────────────────────────────────────────────
申报处理量 50/min 200/min
CPU 使用率 25% 78%
Young GC 频率 10/min 95/min
Young GC 平均耗时 10ms 120ms
堆内存使用率 55% 88%
业务影响:
- 申报提交后,审核结果返回变慢(从 30 秒变成 2 分钟)
- 高峰期系统响应卡顿排查过程
Step 1: 分析 GC 日志
[2024-03-05T09:30:00.123+0800] info: GC (G1 Evacuation Pause)
young=105ms old=0ms humongous=45ms
[2024-03-05T09:30:01.234+0800] info: GC (G1 Humongous Allocation)
Allocated humongous object of size 640KB
[2024-03-05T09:30:01.345+0800] info: GC (G1 Humongous Allocation)
Allocated humongous object of size 720KB关键发现:
- Young GC 耗时 105ms(偏高)
- humongous allocation 频繁出现
- 大对象大小在 600~800 KB 之间
Step 2: 检查 G1 Region 配置
# 检查启动参数
jcmd <pid> VM.flags | grep G1HeapRegionSize
# 输出:-XX:G1HeapRegionSize=1m
# 发现 Region 被设置为 1MB
# 大对象判定阈值 = 1MB × 50% = 512KB
# 600KB > 512KB,所以被判定为大对象Step 3: 录制 JFR 文件
# 启动 JFR 录制 60 秒
jcmd <pid> JFR.start name=analysis01 duration=60s filename=/var/log/analysis01.jfr
# 或者使用 Arthas 工具
jfr start -n analysis01 --duration 60s -f /var/log/analysis01.jfrStep 4: 使用 JProfiler 或者 IDEA 中的 Profiler 分析结果
Memory → Allocation
─────────────────────────────────────────────
Method Allocated Percentage
─────────────────────────────────────────────
AuditProducer.sendAuditMessage() 2.8 GB 82%
└─ byte[] 2.2 GB 65%
└─ char[] 0.6 GB 17%
定位到 sendAuditMessage() 这一行代码Step 5: 代码审查
// AuditProducer.java
@Service
public class AuditProducer {
@Autowired
private ObjectMapper objectMapper;
@Autowired
private RocketMQTemplate rocketMQTemplate;
// 问题代码:AuditProducer.java:78
public void sendAuditMessage(String declarationId) {
// 1. 查询申报主表
Declaration declaration = declarationService.getById(declarationId);
// 2. 查询企业信息
Enterprise enterprise = enterpriseService.getById(declaration.getEnterpriseId());
// 3. 查询发票明细(大表!)
List<InvoiceDetail> invoices = invoiceService.getByDeclarationId(declarationId);
// 平均 200 条,每条 3KB,总共 600KB
// 4. 组装 DTO
AuditDTO dto = new AuditDTO();
dto.setEnterpriseId(enterprise.getEnterpriseId());
dto.setEnterpriseName(enterprise.getEnterpriseName());
dto.setEnterpriseType(enterprise.getEnterpriseType());
dto.setIndustryCode(enterprise.getIndustryCode());
dto.setDeclarationId(declaration.getDeclarationId());
dto.setPeriod(declaration.getPeriod());
dto.setDeclarationType(declaration.getDeclarationType());
dto.setSubmitTime(declaration.getSubmitTime());
// 问题:把整个发票明细列表都放进去了
dto.setInvoices(invoices); // 200 条,600KB
// 计算汇总
dto.setInvoiceTotalAmount(
invoices.stream()
.map(InvoiceDetail::getTotalAmount)
.reduce(BigDecimal.ZERO, BigDecimal::add)
);
dto.setInvoiceCount(invoices.size());
// 5. 序列化发送(问题所在)
try {
byte[] payload = objectMapper.writeValueAsBytes(dto);
// payload 大小 = 720KB!
// 发送到 RocketMQ
rocketMQTemplate.asyncSend("audit-topic", payload, new SendCallback() {
@Override
public void onSuccess(SendResult result) {
log.info("发送成功: {}", result.getMsgId());
}
@Override
public void onException(Throwable e) {
log.error("发送失败", e);
}
});
} catch (JsonProcessingException e) {
log.error("序列化失败", e);
}
}
}Step 6: 分析数据大小
AuditDTO 组成分析:
─────────────────────────────────────────────
基本字段合计 ≈ 200 字节
invoices 列表 200 条 × 3KB = 600KB
- 每条 InvoiceDetail:
- 基本字段:≈ 300 字节
- goodsInfo:2-5KB(JSON 格式的货物/服务明细)
- remark:0-500 字节
─────────────────────────────────────────────
AuditDTO 对象合计 ≈ 600KB
JSON 序列化后:
─────────────────────────────────────────────
- 字段名重复开销:≈ 50KB
- JSON 结构开销:≈ 20KB
- goodsInfo 嵌套 JSON:额外 50KB(字符串转义)
─────────────────────────────────────────────
payload 大小 ≈ 720KB
内存分配分析:
─────────────────────────────────────────────
- AuditDTO 对象:600KB(内存中)
- byte[] payload:720KB(序列化后)
- 每条消息总分配:600KB + 720KB = 1.32MB
- 每分钟 200 条 = 每分钟分配 264MB解决方案
方案对比
| 方案 | 效果 | 改动范围 | 风险 |
|---|---|---|---|
| 1. GZIP 压缩 | payload 75%↓ | 生产者+消费者 | CPU 增加 |
| 2. 分批发送 | payload 80%↓ | 生产者+消费者 | 顺序依赖 |
| 3. 字段精简 | payload 60%↓ | 生产者+消费者 | 需需求确认 |
| 4. Region 调整 | GC 效率提升 | JVM 参数 | 治标不治本 |
方案 1:GZIP 压缩(推荐)
// 序列化工具类
public class SerializationUtils {
private static final ObjectMapper objectMapper = new ObjectMapper();
// 压缩序列化
public static byte[] serializeWithGzip(Object obj) throws IOException {
byte[] jsonBytes = objectMapper.writeValueAsBytes(obj);
ByteArrayOutputStream baos = new ByteArrayOutputStream();
try (GZIPOutputStream gzip = new GZIPOutputStream(baos)) {
gzip.write(jsonBytes);
}
return baos.toByteArray();
}
// 解压反序列化
public static <T> T deserializeWithGzip(byte[] compressed, Class<T> clazz)
throws IOException {
try (GZIPInputStream gzip = new GZIPInputStream(new ByteArrayInputStream(compressed))) {
return objectMapper.readValue(gzip, clazz);
}
}
}
// 生产者改造
public void sendAuditMessage(String declarationId) {
AuditDTO dto = buildDTO(declarationId);
byte[] payload = SerializationUtils.serializeWithGzip(dto);
// 720KB → 180KB
rocketMQTemplate.asyncSend("audit-topic", payload, sendCallback);
}
// 消费者改造
@RocketMQMessageListener(topic = "audit-topic", consumerGroup = "audit-group")
public class AuditConsumer implements RocketMQListener<byte[]> {
@Override
public void onMessage(byte[] payload) {
AuditDTO dto = SerializationUtils.deserializeWithGzip(payload, AuditDTO.class);
processAudit(dto);
}
}效果预估:
JSON 数据特点:重复字段名多,适合压缩
测试结果(100 条真实数据):
─────────────────────────────────────────────
原始 JSON 720KB
GZIP 压缩后 180KB(压缩率 75%)
压缩耗时 3-5ms
解压耗时 2-3ms
─────────────────────────────────────────────方案 2: 分批发送
// 如果发票数量超过 40 条,分批发送
public void sendAuditMessage(String declarationId) {
AuditDTO dto = buildDTO(declarationId);
List<InvoiceDetail> invoices = dto.getInvoices();
if (invoices.size() <= 40) {
// 发票数量少,直接发送
sendSingleMessage(dto);
} else {
// 发票数量多,分批发送
dto.setInvoices(null); // 先发基本信息
// 消息 1:基本信息(5KB)
sendSingleMessage(dto, 1, 3);
// 消息 2:发票明细(前半部分,300KB)
AuditDTO dto2 = new AuditDTO();
dto2.setDeclarationId(declarationId);
dto2.setInvoices(invoices.subList(0, invoices.size()/2));
sendSingleMessage(dto2, 2, 3);
// 消息 3:发票明细(后半部分,300KB)
AuditDTO dto3 = new AuditDTO();
dto3.setDeclarationId(declarationId);
dto3.setInvoices(invoices.subList(invoices.size()/2, invoices.size()));
sendSingleMessage(dto3, 3, 3);
}
}适用场景: 发票数量多的情况
方案 3: 字段精简 (需要和上下游确认)
// 与审核团队确认后,精简非必要字段
public class AuditLiteDTO {
// 精简的发票信息(不传 goodsInfo 和 remark)
private List<InvoiceLite> invoices;
}
public class InvoiceLite {
private String invoiceId;
private String invoiceCode;
private String invoiceNumber;
private Date invoiceDate;
private BigDecimal totalAmount;
// 不传 goodsInfo 和 remark
}效果预估:
每条 InvoiceDetail:3KB → 0.5KB(精简 83%)
AuditLiteDTO:600KB → 100KB(精简 83%)
JSON 序列化后:720KB → 120KB方案 4: Region 大小调整 (JVM 参数层面)
# 移除或调整 Region 大小
# 原:-XX:G1HeapRegionSize=1m(导致 512KB+ 被判定为大对象)
# 改:-XX:G1HeapRegionSize=4m(默认值,大对象阈值 2MB)
# 或者直接移除该参数,使用默认值注意:这只是治标不治本,根本还是要减少大对象分配
最终方案 (组合使用):
团队决策:
─────────────────────────────────────────────
阶段 1(紧急):GZIP 压缩
- 改动最小,风险最低
- 立即可上线
阶段 2(后续):字段精简
- 需要与审核团队确认需求
- 进一步优化效果
参数调整:移除 G1HeapRegionSize 配置,使用默认值效果验证
测试环境(100 条真实申报数据):
─────────────────────────────────────────────
指标 修改前 GZIP 后
─────────────────────────────────────────────
payload 大小 720KB 180KB
序列化耗时 5ms 8ms
反序列化耗时 4ms 6ms
─────────────────────────────────────────────
生产环境监控(上线后 3 天):
─────────────────────────────────────────────
指标 修改前 修改后 变化
─────────────────────────────────────────────
CPU 使用率 78% 62% ↓20%
Young GC 频率 95/min 45/min ↓53%
Young GC 耗时 120ms 55ms ↓54%
堆内存使用率 88% 72% ↓18%
审核响应时间 2 分钟 40 秒 ↓67%
─────────────────────────────────────────────
效果分析:
─────────────────────────────────────────────
1. AuditDTO 对象本身还在(600KB 内存分配不变)
2. payload 从 720KB 降到 180KB(↓75%)
3. GZIP 压缩增加 CPU 开销(5-8%)
4. 综合效果:GC 压力下降,CPU 也下降(因为 GC 开销降低更多)
结论:优化效果显著面试模板
GC 频繁排查经历(缓存问题)
背景:订单服务,JDK8,堆内存 4GB
问题:接口响应从 50ms 增长到 500ms,CPU 持续 90%+
排查过程:
- 使用
jstat -gcutil发现 Minor GC 频率从 10 次/分钟 增长到 100 次/分钟- GC 日志显示老年代使用率持续 85%+
jmap导出堆快照,MAT 分析发现 OrderCache 缓存未设置过期策略,占用 2GB解决方案:
- 代码层面:使用 Caffeine 替换 HashMap,设置最大容量和过期时间
- 参数层面:调整堆内存从 4G 到 6G
效果:GC 频率恢复正常,接口响应回到 50ms,CPU 降到 40%
内存泄漏排查经历(ThreadLocal 问题)
背景:报表服务,JDK8,每日定时导出 Excel 报表
问题:老年代使用率每天增长 5%,从 60% 增长到 95%,每周触发 Full GC
排查过程:
jstat监控发现老年代持续增长,Minor GC 后不降反升(内存泄漏特征)jmap导出 Heap Dump,MAT 分析发现 XSSFWorkbook 占用 3GB- 查看引用链,发现 ThreadLocal 中存储的 Workbook 未清理
- 定位代码:Excel 导出后未调用
workbookHolder.remove()和workbook.close()解决方案:
- 使用
try-with-resources确保 Workbook 关闭- 在
finally块中调用ThreadLocal.remove()- 长期方案:移除 ThreadLocal 存储,改用局部变量传递
效果:老年代稳定在 45%,Full GC 消失
大对象调优经历
背景:申报审核服务,JDK17,每月 1-15 号高峰期每分钟处理 200 条申报
问题:CPU 使用率 78%,Young GC 频率 95/min,耗时 120ms,审核响应从 30 秒变成 2 分钟
排查过程:
- GC 日志发现
humongous allocation频繁,每分钟分配多个 600-800KB 大对象- JFR 定位到
AuditProducer.sendAuditMessage方法占用 82% 内存分配- 代码审查发现每条申报消息包含 200 条发票明细(600KB),JSON 序列化后 720KB
- G1 Region 被设置为 1MB,大对象阈值 512KB,600KB+ 被判定为大对象
解决方案:
- 代码层面:GZIP 压缩,payload 从 720KB 降到 180KB(↓75%)
- 参数层面:移除
-XX:G1HeapRegionSize=1m,使用默认值- 后续优化:与审核团队确认后精简非必要字段
效果:Young GC 频率 95/min → 45/min(↓53%),CPU 78% → 62%(↓20%),审核响应 2 分钟 → 40 秒