LinkedList
概述
LinkedList 同时实现了 List 接口和 Deque 接口,也就是说它既可以作为一个顺序容器,也可以作为一个队列,又可以作为一个栈进行使用。关于栈或队列,现在首选的容器是 ArrayDeque,在用作栈或队列时性能比 LinkedList 要好。
LinkedList 的结构是双向链表,所以一切与下标相关的操作都是线性时间,而在首尾增加或删除元素的操作都是常数时间。为了追求性能它没有实现同步,如果需要多个行程访问则需要使用 Collections.synchronizedList() 进行包装
底层实现
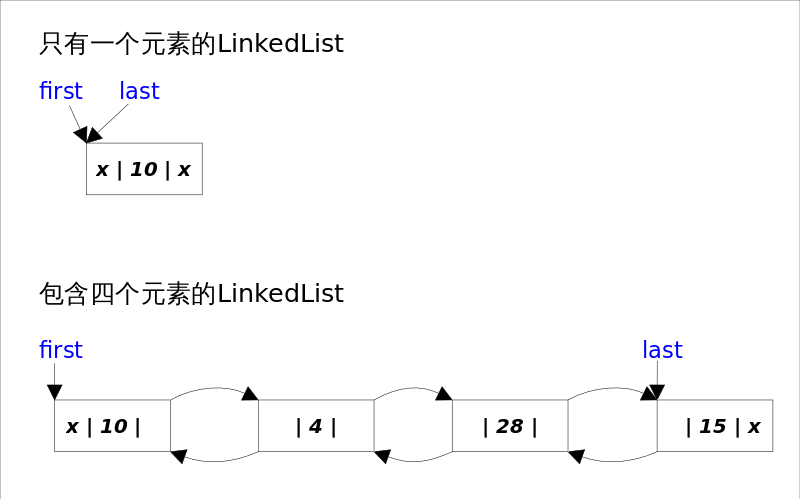
底层是双向链表实现,双向链表的每个节点用一个内部类 Node 来表示,内部类中包含三个内容:节点数据、上一个元素、下一个元素。同时链表中还用一个头指针和尾指针表示第一个元素和最后一个元素。当链表为空时,头指针和尾指针都指向 null
private static class Node<E> {
// 节点数据
E item;
// 下一个节点
Node<E> next;
// 下一个节点
Node<E> prev;
}// 头节点
transient Node<E> first;
// 尾节点
transient Node<E> last;构造方法
构造方法的实现比较简单,如果传入一个集合到构造方法中就把这个集合的所有元素构造成一个双向链表
public LinkedList() {
}
public LinkedList(Collection<? extends E> c) {
this();
addAll(c);
}添加元素
添加元素提供了两个方法
添加到链表末尾。因为有 last 引用指向链表末尾节点,所以插入到链表末尾的操作的时间花费是常数时间。
javapublic boolean add(E e) { linkLast(e); return true; } void linkLast(E e) { // 获取链表末尾元素 final Node<E> l = last; // 把新插入的元素实例化为链表节点 final Node<E> newNode = new Node<>(l, e, null); // 把链表尾指针指向新节点 last = newNode; // 如果末尾元素是空(说明这个链表是空链表),那就把链表头指针指向新节点 if (l == null) first = newNode; // 把原有末尾元素的下一个元素指向新元素 else l.next = newNode; size++; modCount++; }add 方法工作原理
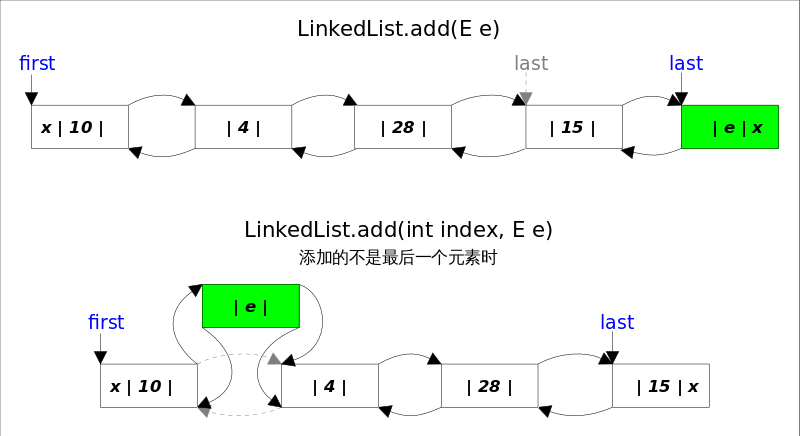
按指定下标插入元素。先使用线性查找具体位置,然后需要修改相关引用完成插入。
javapublic void add(int index, E element) { // 首先检查索引是否越界 checkPositionIndex(index); // 如果索引等于链表长度,说明插入到末尾 if (index == size) linkLast(element); // 如果不是,那就根据index查找需要插入的位置,再完成引用的修改完成操作 else linkBefore(element, node(index)); } Node<E> node(int index) { // 查找节点的逻辑 // 把index和一般容量作比较 // 来判断index靠近链表的头端还是尾端,加快搜索效率 if (index < (size >> 1)) { Node<E> x = first; for (int i = 0; i < index; i++) x = x.next; return x; } else { Node<E> x = last; for (int i = size - 1; i > index; i--) x = x.prev; return x; } }
获取元素
常用的获取元素的方式有获取第一个元素、获取最后一个元素、按索引获取元素
获取首尾元素的实现很简单,因为链表有维护头尾指针
public E getFirst() {
final Node<E> f = first;
if (f == null)
throw new NoSuchElementException();
return f.item;
}
public E getLast() {
final Node<E> l = last;
if (l == null)
throw new NoSuchElementException();
return l.item;
}按索引获取元素的话,需要使用到上面提到的 Node<E> node(int index) 方法,根据索引来决定是从前往后遍历还是从后往前遍历
public E get(int index) {
checkElementIndex(index);
return node(index).item;
}删除元素
删除元素提供了四个方法
删除第一个元素
删除最后一个元素
由于链表有头尾指针,所以完成这两个操作还是比较简单的,原理基本上是切断第一个或最后一个元素在链表中的引用
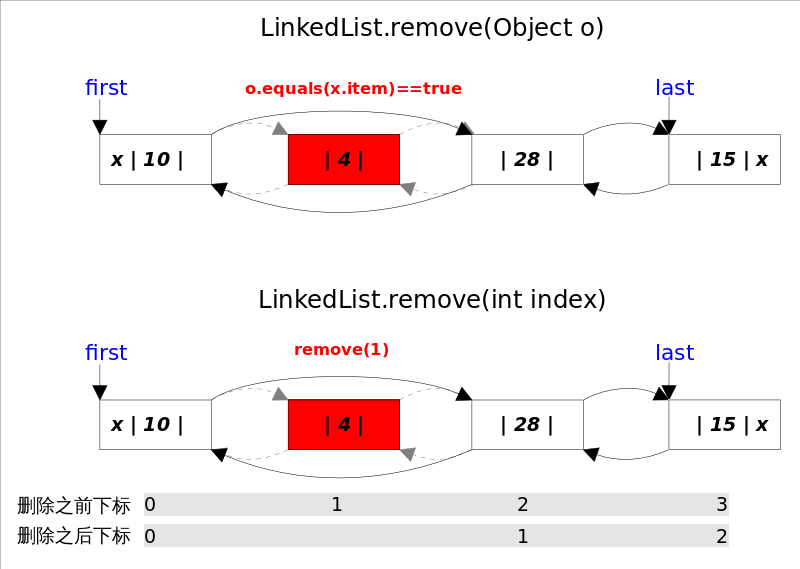
javapublic E removeFirst() { final Node<E> f = first; if (f == null) throw new NoSuchElementException(); return unlinkFirst(f); } private E unlinkFirst(Node<E> f) { // assert f == first && f != null; final E element = f.item; final Node<E> next = f.next; f.item = null; f.next = null; // help GC first = next; if (next == null) last = null; else next.prev = null; size--; modCount++; return element; } public E removeLast() { final Node<E> l = last; if (l == null) throw new NoSuchElementException(); return unlinkLast(l); } private E unlinkLast(Node<E> l) { // assert l == last && l != null; final E element = l.item; final Node<E> prev = l.prev; l.item = null; l.prev = null; // help GC last = prev; if (prev == null) first = null; else prev.next = null; size--; modCount++; return element; }按元素删除,指删除第一次出现的这个元素,判断依据是使用 equals 方法;也可以删除
null元素,所以判断依据要分开按索引删
javapublic boolean remove(Object o) { if (o == null) { for (Node<E> x = first; x != null; x = x.next) { if (x.item == null) { unlink(x); return true; } } } else { for (Node<E> x = first; x != null; x = x.next) { if (o.equals(x.item)) { unlink(x); return true; } } } return false; } public E remove(int index) { checkElementIndex(index); return unlink(node(index)); } E unlink(Node<E> x) { // assert x != null; final E element = x.item; final Node<E> next = x.next; final Node<E> prev = x.prev; if (prev == null) {// 第一个元素 first = next; } else { prev.next = next; x.prev = null; } if (next == null) {// 最后一个元素 last = prev; } else { next.prev = prev; x.next = null; } x.item = null; // GC size--; modCount++; return element; }按元素删除和按索引删除方法的工作原理