组合模式
定义:通过将单个对象(叶子结点)和组合对象(树枝结点)用相同的接口进行表示,使客户端对单个对象和组合对象保持一致的处理方式
组合关系与聚合关系的区别:组合关系中的各个部分具有相同的生命周期,如人体的器官;聚合关系中的各个部分具有独立的生命周期,如电脑中的鼠标、键盘
适用场景:
- 希望客户端可以忽略组合对象与单个对象的差异
- 对象具备整体和部分,呈树形结构(操作系统目录结构、公司组织架构等)
优点:
- 清楚地定义分层次的复杂对象,表示对象的全部或者部分层次
- 让客户端忽略层次的差异,方便对整个层级结构进行控制
- 符合开闭原则
缺点:
- 限制类型时会较为复杂
- 使得设计变得更加抽象
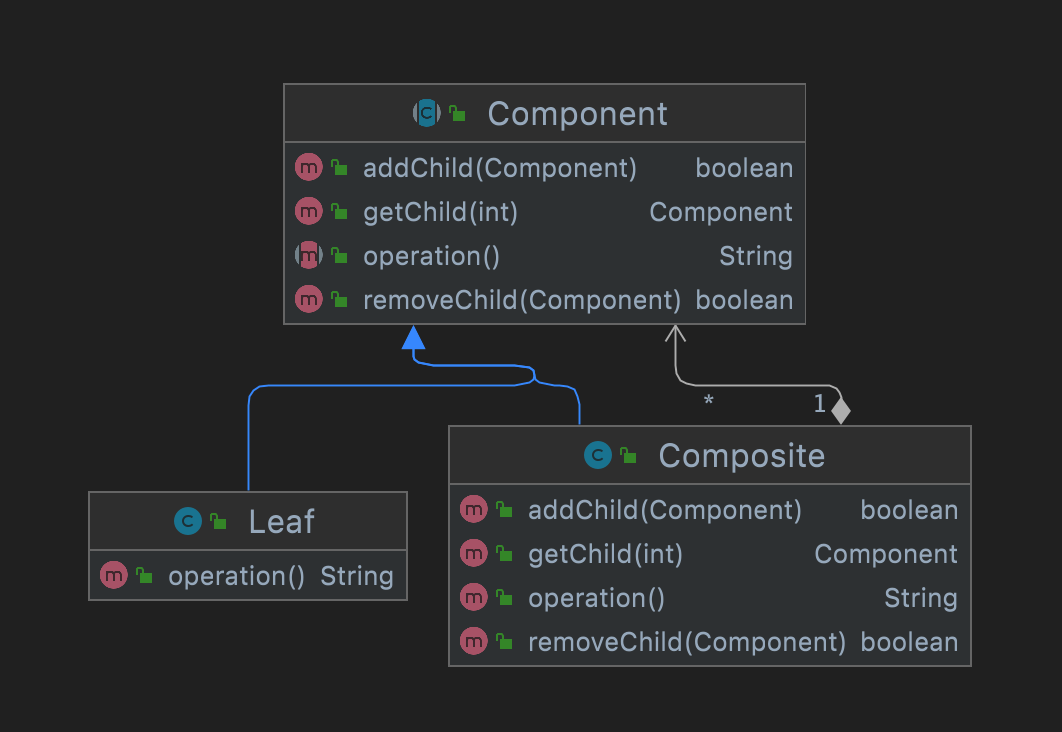
透明模式写法
透明模式
透明组合模式把所有的公共方法都定义在 抽象根节点(Component) 中,这样 叶子结点(Leaf) 和 树枝结点(Composite) 都具备完全一致的接口,只不过各自拥有不同的实现
这样做的好处是:客户端使用的时候无需分辨是叶子结点(Leaf) 还是 树枝结点(Composite) ,它们具备一致的行为;但是缺点是 叶子结点(Leaf) 会继承得到一些它所不需要的方法(管理子类的方法),违背接口隔离原则
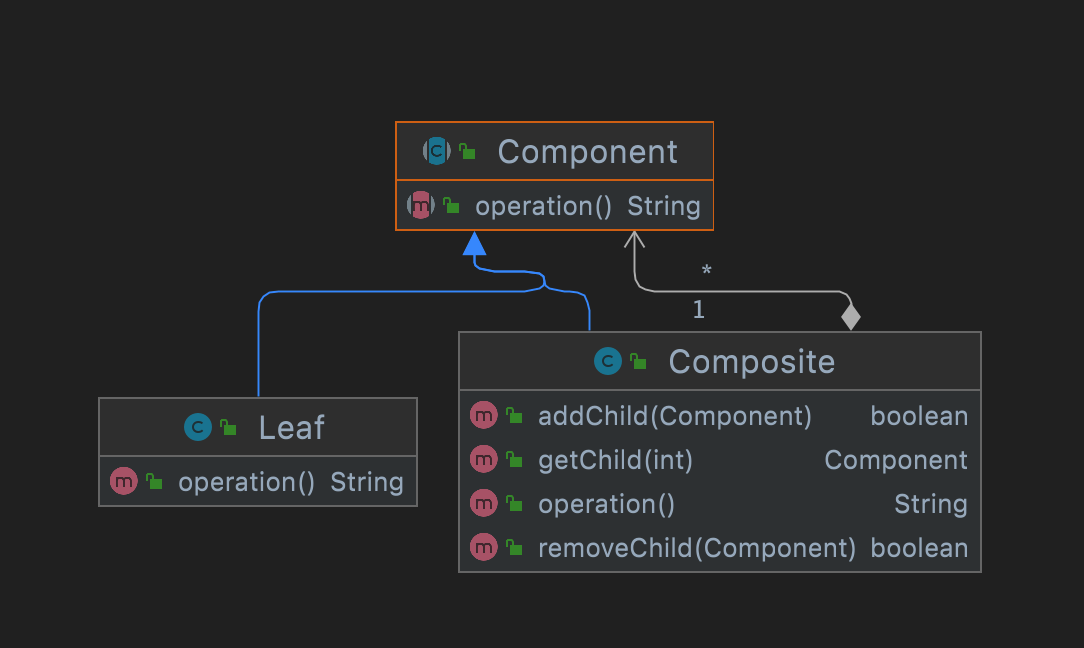
安全模式
安全组合模式的写法在 抽象根节点(Component) 中只规定了最基础的一致行为,而把 树枝结点(Composite) 本身的方法放在自己类中
这样做的好处是:接口定义职责清晰,符合单一职责原则、接口隔离原则;但是缺点是:客户端需要区分 树枝结点(Composite) 和 叶子结点(Leaf) 才能正确处理各层级的操作,无法简单依赖抽象,违背依赖倒置原则
透明模式和安全模式的选择
既然组合模式被分为两种实现,那么肯定会在不同场合下某一种会更加合适
当系统中绝大多数层次具备相同的公共行为时,采用透明组合模式会更好,代价是为少数层次结点引入不需要的方法
当系统中各个层次差异性行为较多或者树结点层次相对稳定时,采用安全组合模式会更好
示例
以文件系统为例,电脑的文件系统是一个典型的树形结构,包含文件夹和文件,而文件夹下面可以包含文件夹和文件。那么文件夹就是 树枝结点(Composite) ,文件就是 叶子结点(Leaf) 。这里使用安全组合模式实现,可以避免文件(叶子结点)引入冗余方法
顶层抽象组件 Directory
public abstract class Directory {
protected String name;
public Directory(String name) {
this.name = name;
}
public abstract void show();
}文件 File
public class File extends Directory {
public File(String name) {
super(name);
}
@Override
public void show() {
System.out.println(this.name);
}
}文件夹 Folder
public class Folder extends Directory {
private List<Directory> dirs;
private Integer level;
public Folder(String name,Integer level) {
super(name);
this.level = level;
this.dirs = new ArrayList<Directory>();
}
@Override
public void show() {
System.out.println(this.name);
for (Directory dir : this.dirs) {
//控制显示格式
if(this.level != null){
for(int i = 0; i < this.level; i ++){
//打印空格控制格式
System.out.print(" ");
}
for(int i = 0; i < this.level; i ++){
//每一行开始打印一个+号
if(i == 0){ System.out.print("+"); }
System.out.print("-");
}
}
//打印名称
dir.show();
}
}
public boolean add(Directory dir) {
return this.dirs.add(dir);
}
public boolean remove(Directory dir) {
return this.dirs.remove(dir);
}
public Directory get(int index) {
return this.dirs.get(index);
}
public void list(){
for (Directory dir : this.dirs) {
System.out.println(dir.name);
}
}
}客户端使用
class Test {
public static void main(String[] args) {
System.out.println("============安全组合模式===========");
File qq = new File("QQ.exe");
File wx = new File("微信.exe");
Folder office = new Folder("办公软件",2);
File word = new File("Word.exe");
File ppt = new File("PowerPoint.exe");
File excel = new File("Excel.exe");
office.add(word);
office.add(ppt);
office.add(excel);
Folder wps = new Folder("金山软件",3);
wps.add(new File("WPS.exe"));
office.add(wps);
Folder root = new Folder("根目录",1);
root.add(qq);
root.add(wx);
root.add(office);
System.out.println("----------show()方法效果-----------");
root.show();
System.out.println("----------list()方法效果-----------");
root.list();
}
}组合模式在源码中的应用
HashMap
HashMap 中的 putAll() 方法,方法传入的是一个 Map 对象,Map 对象是一个抽象组件,这个组件只支持键值对的存储格式;HashMap 对象是一个树枝结点,HashMap 中的 Node 对象是一个叶子结点,HashMap 中的存储方式就是一个静态内部类的数组 Node<K, V>[] tab
public void putAll(Map<? extends K, ? extends V> m) {
putMapEntries(m, true);
}
final void putMapEntries(Map<? extends K, ? extends V> m, boolean evict) {
int s = m.size();
if (s > 0) {
if (table == null) { // pre-size
float ft = ((float)s / loadFactor) + 1.0F;
int t = ((ft < (float)MAXIMUM_CAPACITY) ?
(int)ft : MAXIMUM_CAPACITY);
if (t > threshold)
threshold = tableSizeFor(t);
}
else if (s > threshold)
resize();
for (Map.Entry<? extends K, ? extends V> e : m.entrySet()) {
K key = e.getKey();
V value = e.getValue();
putVal(hash(key), key, value, false, evict);
}
}
}ArrayList
和 HashMap 相似,ArrayList 也有一个 addAll() 方法,传入的参数是 ArrayList 的父类 Collection
public class ArrayList<E> extends AbstractList<E> implements List<E>, RandomAccess, Cloneable, java.io.Serializable {
public boolean addAll(Collection<? extends E> c) {
Object[] a = c.toArray();
int numNew = a.length;
ensureCapacityInternal(size + numNew); // Increments modCount
System.arraycopy(a, 0, elementData, size, numNew);
size += numNew;
return numNew != 0;
}
}MyBatis
MyBatis 在解析mapper.xml文件中的SQL语句时,设计了一个非常关键的类:SqlNode ,xml文件中的每一个Node都会被解析成一个 SqlNode 对象,最后把所有的 SqlNode 拼装到一起就成了一条完整的SQL语句
顶层抽象组件
public interface SqlNode {
boolean apply(DynamicContext context);
}可以看到 SQLNode 的类图,实现类也比较容易理解,SQL语句中有If条件的就解析成 IFSqlNode 对象

apply() 方法会根据传入的 context,参数解析该 SqlNode 所记录的SQL片段,并调用 DynamicContext 的 appendSql() 方法将解析后的SQL片段追加到 DynamicContext.sqlBuilder 中保存。当SQL语句中所有的 SqlNode 都解析完成后,可以通过 DynamicContext.getSql() 获取一条完整的SQL语句