LinkedHashMap 与 LinkedHashSet
就像 TreeMap 与 TreeSet、HashMap 与 HashSet 一样,LinkedHashSet 和 LinkedHashMap 其实也是一回事。LinkedHashSet 和 LinkedHashMap 在 Java 里也有着相同的实现,前者仅仅是对后者做了一层包装。
底层实现
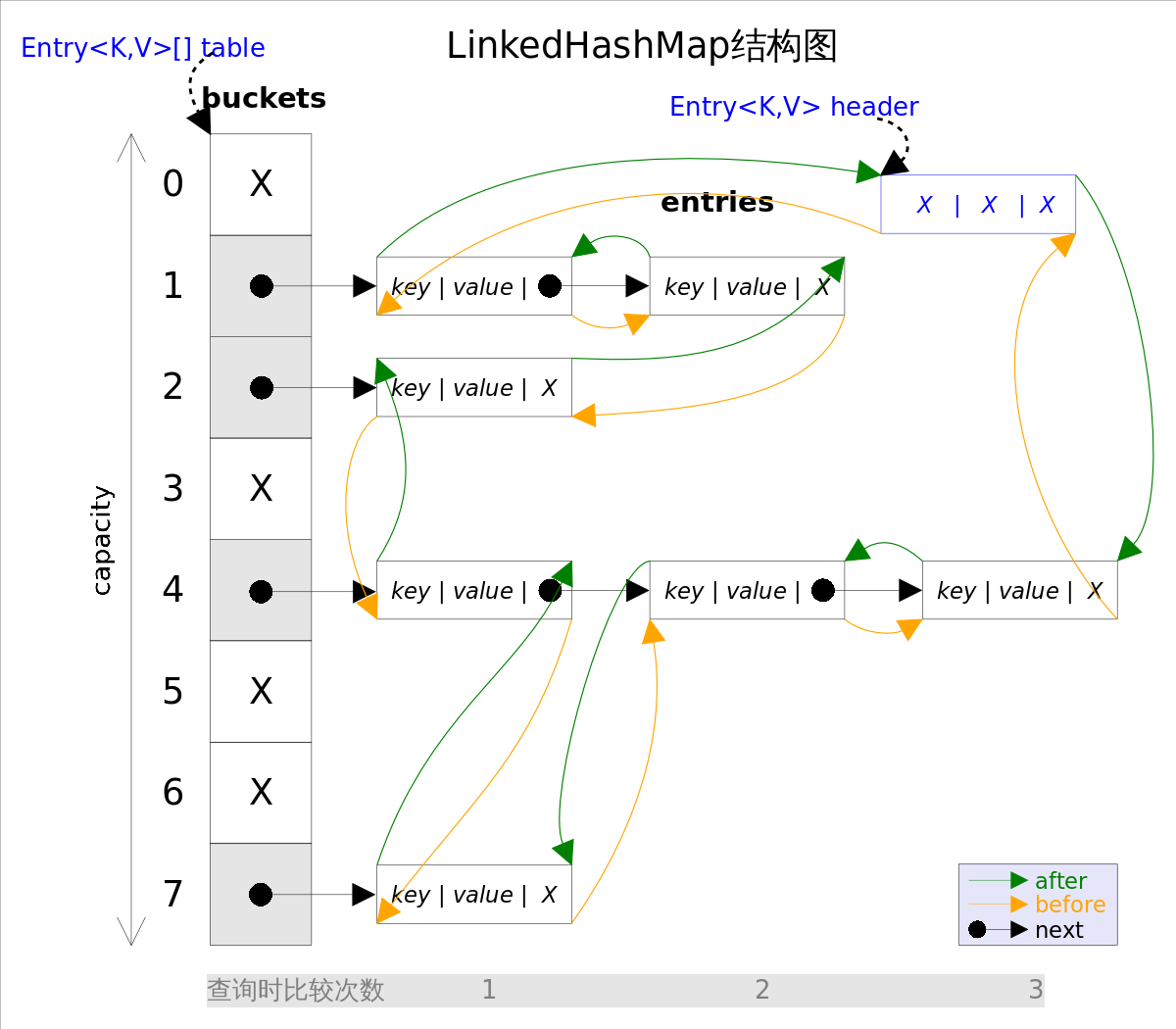
LinkedHashMap 从名字上可以看出该容器是 LinkedList 和 HashMap 的混合体,也就是说它同时满足 HashMap 和 LinkedList 的某些特性。可将LinkedHashMap 看作采用 LinkedList 增强的 HashMap。
LinkedHashMap 和 HashMap 区别是采用双向链表的形式把所有的 entry 连接起来,这样可以保证元素的迭代顺序和插入顺序相同
public class LinkedHashMap<K,V> extends HashMap<K,V> implements Map<K,V> {
// 双向链表的头指针
transient LinkedHashMap.Entry<K,V> head;
// 双向链表的尾指针
transient LinkedHashMap.Entry<K,V> tail;
static class Entry<K,V> extends HashMap.Node<K,V> {
// 在原有Node的基础上加入前后节点指针
Entry<K,V> before, after;
Entry(int hash, K key, V value, Node<K,V> next) {
super(hash, key, value, next);
}
}
}其中有一个属性 accessOrder,默认是 false,按插入顺序排序;如果设置为 true,是按访问顺序排序,也就是说每次调用 get 方法都重新调整链表元素顺序!
/**
* The iteration ordering method for this linked hash map: <tt>true</tt>
* for access-order, <tt>false</tt> for insertion-order.
*
* @serial
*/
final boolean accessOrder;查看 HashMap 源码可以看到留了几个方法为 LinkedHashMap 服务
// Callbacks to allow LinkedHashMap post-actions
// 访问节点的回调
void afterNodeAccess(Node<K,V> p) { }
// 插入节点的回调
void afterNodeInsertion(boolean evict) { }
// 删除节点的回调
void afterNodeRemoval(Node<K,V> p) { }LinkedHashMap 结构图
添加元素
LinkedHashMap 添加元素包括两个步骤
- 把元素添加到 Node<K,V>[] table 中
- 把元素添加到双向链表的尾部
添加元素和 HashMap 的过程类似,LinkedHashMap 中添加元素其实使用的是 HashMap 的 put 方法,但是 LinkedHashMap 中重写了两个方法,丰富了这个方法的功能
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) {
//...
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
// 重写
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
// ...
if (++size > threshold)
resize();
// 重写
afterNodeInsertion(evict);
return null;
}LinkedHashMap 重写了 newNode 方法,新点节点插入到链表最后
Node<K,V> newNode(int hash, K key, V value, Node<K,V> e) {
LinkedHashMapEntry<K,V> p = new LinkedHashMapEntry<K,V>(hash, key, value, e);
linkNodeLast(p);
return p;
}
private void linkNodeLast(LinkedHashMapEntry<K,V> p) {
LinkedHashMapEntry<K,V> last = tail;
// tail指向新插入点节点
tail = p;
if (last == null)
head = p;
else {
// last->p
p.before = last;
last.after = p;
}
}LinkedHashMap 重写了 afterNodeInsertion,这个方法是判断插入新的节点,是否需要删除第一个节点,但是因为 removeEldestEntry 返回 false,所以不会删除节点
void afterNodeInsertion(boolean evict) { // possibly remove eldest
LinkedHashMapEntry<K,V> first;
if (evict && (first = head) != null && removeEldestEntry(first)) {
K key = first.key;
removeNode(hash(key), key, null, false, true);
}
}
protected boolean removeEldestEntry(Map.Entry<K,V> eldest) {
return false;
}获取元素
默认 accessOrder 为 false 的情况下,获取元素是就是调用 HashMap 的获取元素的方法
如果 accessOrder 为 true,那么在获取元素的基础上,还要按访问顺序重新排序元素
public V get(Object key) {
Node<K,V> e;
if ((e = getNode(hash(key), key)) == null)
return null;
// 访问顺序,访问后需要重新排列
if (accessOrder)
afterNodeAccess(e);
return e.value;
}删除元素
LinkedHashMap 添加元素包括两个步骤
- 把元素添加从 Node<K,V>[] table 移除
- 把元素添加从双向链表中移除
final Node<K,V> removeNode(int hash, Object key, Object value, boolean matchValue, boolean movable) {
Node<K,V>[] tab; Node<K,V> p; int n, index;
if ((tab = table) != null && (n = tab.length) > 0 &&
(p = tab[index = (n - 1) & hash]) != null) {
// 查找需要删除的元素
Node<K,V> node = null, e; K k; V v;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
node = p;
else if ((e = p.next) != null) {
if (p instanceof TreeNode)
node = ((TreeNode<K,V>)p).getTreeNode(hash, key);
else {
do {
if (e.hash == hash &&
((k = e.key) == key ||
(key != null && key.equals(k)))) {
node = e;
break;
}
p = e;
} while ((e = e.next) != null);
}
}
if (node != null && (!matchValue || (v = node.value) == value ||
(value != null && value.equals(v)))) {
// 把元素从table中删除
if (node instanceof TreeNode)
((TreeNode<K,V>)node).removeTreeNode(this, tab, movable);
else if (node == p)
tab[index] = node.next;
else
p.next = node.next;
++modCount;
--size;
// 修改双向链表中的引用,删除元素
afterNodeRemoval(node);
return node;
}
}
return null;
}经典用法
LinkedHashMap 除了可以保证迭代顺序外,还有一个非常有用的用法: 可以轻松实现一个采用了 FIFO 替换策略的缓存。
具体说来,LinkedHashMap有一个方法 protected boolean removeEldestEntry(Map.Entry<K,V> eldest),该方法的作用是告诉 Map 是否要删除“最老”的 Entry,所谓最老就是当前 Map 中最早插入的 Entry。
LinkedHashMap 中默认是返回 false,所以插入元素后是不会移除元素的。如果该方法返回 true,最老的那个元素就会被删除。在每次插入新元素的之后 LinkedHashMap 会调用 removeEldestEntry() 是否要删除最老的元素。
由以上信息可以得出只需要在子类中重载该方法,当元素个数超过一定数量时让 removeEldestEntry() 返回 true,就能够实现一个固定大小的 FIFO 策略的缓存。
/** 一个固定大小的FIFO替换策略的缓存 */
public class FIFOCache<K, V> extends LinkedHashMap<K, V>{
private final int cacheSize;
public FIFOCache(int cacheSize){
this.cacheSize = cacheSize;
}
// 当Entry个数超过cacheSize时,删除最老的Entry
@Override
protected boolean removeEldestEntry(Map.Entry<K,V> eldest) {
return size() > cacheSize;
}
}LinkedHashSet
LinkedHashSet 是对 LinkedHashMap 的简单包装,对 LinkedHashSet 的函数调用都会转换成合适的 LinkedHashMap 方法,因此LinkedHashSet的实现非常简单,这里不再赘述。
public class LinkedHashSet<E>
extends HashSet<E>
implements Set<E>, Cloneable, java.io.Serializable {
......
// LinkedHashSet里面有一个LinkedHashMap
public LinkedHashSet(int initialCapacity, float loadFactor) {
map = new LinkedHashMap<>(initialCapacity, loadFactor);
}
......
public boolean add(E e) {//简单的方法转换
return map.put(e, PRESENT)==null;
}
......
}